Related concepts of video coding
Video coding standard
The original video file is very large, not suitable for storage and transmission. For example, according to the smallest YU(Cb)V(Cr)4:2:0 format, the SD resolution is 1280*720, and the frame rate is 25fp/s. How big is the data volume?
Each frame is 1280×720×8×(1+1/4+1/4)/8=1382400Bytes= 1350KB, about=1.318359375M, and then multiplied by 25 frames, the original data per second is 1.32M×25=33M. Think about it, this is just a video file size of 1 million pixels and 1s. If it is more high-definition, the huge amount of data will be a huge burden for our ordinary network bandwidth and storage.
Video files are compressed according to a certain method, also called encoding, which can greatly reduce the file size, which is obviously more conducive to the transmission, storage and application of video files. And this compression standard was formulated, called the video coding standard, in order to be accepted by the industry and users.
Regarding video coding standards, various companies, standardization organizations, and industry associations are involved. At present, the main organizations that formulate video coding standards are mainly these:
- ISO/IEC MPEG. The MPEG organization recognized by ISO and IEC mainly formulates video coding standards for the MPEG series, MPEG-1, MPEG-2, MPEG-3, MPEG-4, MPEG-7 and other standards. The latest MPEG-21 is under development .
- ITU-T. ITU-T is the telecommunications standardization department under the International Telecommunication Union. The video coding standards developed mainly include H.261, H.262, H.263, H.264, H.265, H.266, etc.
- Google’s video standards are VP9, VP10, etc.
- Apple’s QUICKTime.
- China AVS, AVS2. The SAVC coding standard for security video surveillance formulated by the Chinese security industry.
- SMPTE of the American Motion Picture Association.
- Microsoft’s WMV.
- Microsoft, Google, Apple and other companies have formed an alliance for open media (alliance for open media) and launched a new video coding standard AV1, AV2.
| Organization | Coding standard |
| ISO/IEC MPEG | MPEG-1,MPEG-2,MPEG-4/AVC,MPEG-H Part2/HEVC |
| ITU-T | H.261,H.262,H.263,H.264/AVC,H.265/HEVC,H.266/VVC |
| SMPTE | VC-1,VC-2,VC-3,VC-5 |
| AOM | AV1, AV2 |
| VP3,VP6,VP7,VP8,VP9,VP10 | |
| Apple | QuickTime |
| China Standardization Association | AVS,AVS2,AVS3 |
| China Security Industry | SAVC |
| Microsoft | WMV |
Video encoding compression method
Video compression usually includes two processes: encoding and decoding. Encoding is to convert the original video data into a compressed format for transmission and storage. Decoding is to convert the compressed video file back to the original video.
The key to compression is to remove redundant information in the video file. The main video coding compression methods include entropy coding, dictionary coding, and motion compensation. The detailed theory can be found in the reference material at the end of the article.
Video encoding format
In order to meet the needs of storing and playing video, different video file formats are artificially set to put video and audio in one file.
Therefore, video files of different formats must be opened and played with a matching player.
| Code name | describe | extension name |
| Flash Video | A popular network video packaging format developed by Adobe Flash. | .flv |
| AVI | Developed by Microsoft, Audio Video Interactive, is to mix video and audio coding together for storage. | .avi |
| WMV | It was also developed by Microsoft. | .wmv/.asf |
| MPEG | MPEG-approved packaging format, as well as a simplified mobile phone version. | .dat,.vob,.mpg/.mpeg,.mp4,.3gp |
| Matroska | The new multimedia encapsulation format is very interactive. | .mkv |
| Real Video | It is easier to make than H.264 encoding. | .rm/.rmvb |
| QuickTime | Developed by Apple, in addition to video and audio, it can also support pictures, text, etc. | .mov,.qt |
| Ogg | Completely open multimedia system project. | .ogg,.ogv,.oga |
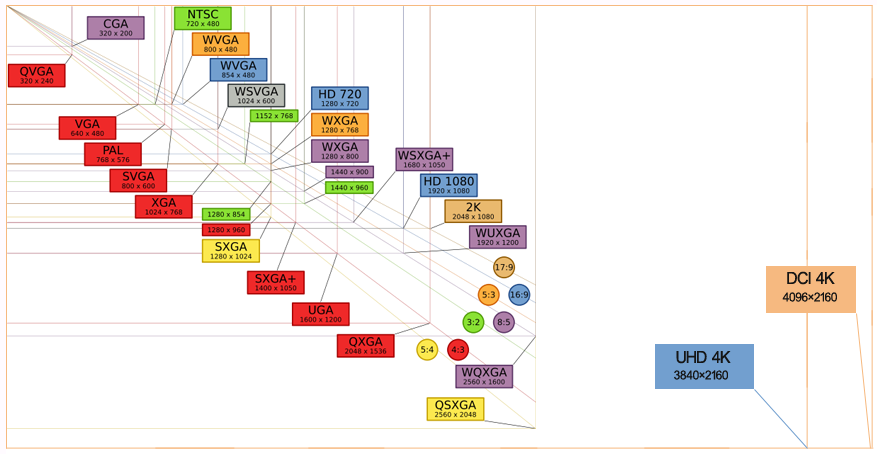
Resolution
| Standard | Resolution | Horizontal to vertical ratio |
| QCIF | 176 x 144 | 1.22:1 |
| CIF | 352 x 288 | 1.22:1 |
| 4CIF | 704 x 576 | 1.22:1 |
| D1 | 720 x 576 | 4:3 |
| SD | 720 x 576 | 4:3 |
| HD | 1280 × 720 | 16:9 |
| Full HD | 1920 × 1080 | 16:9 |
| 3.0MP/QXGA | 2048 × 1536 | 4:3 |
| 4.0MP/1440P | 2560 × 1440 | 16:9 |
| 5.0MP | 2592 × 1944 | 4:3 |
| UHD 4K | 3840 × 2160 | 16:9 |
| DCI 4K | 4096 × 2160 | about 17:9 |
| Ultra HD 8K | 7680 × 4320 | 16:9 |
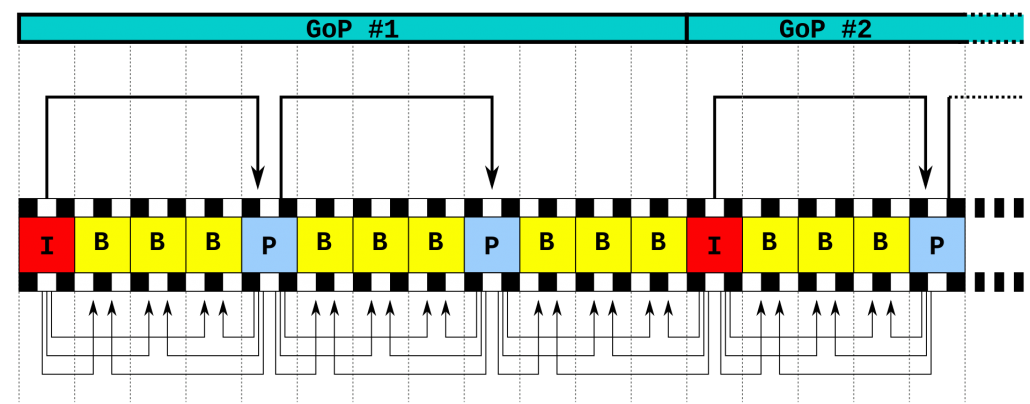
Frame rate/frame/group (GOP)
Frame rate
Frame rate is a measure used to measure the number of still frames of a video display. The unit of measurement is “Frame per Second” (Frame per Second, FPS) or “Hertz”. Generally speaking, FPS is used to describe how many frames of still pictures the video plays per second.
Due to the special physiological structure of the human eye, if the frame rate of the image being viewed is higher than about 10 to 12 frames per second, it will be considered to be coherent. This phenomenon is called persistence of vision. This is why the movie film is shot frame by frame, but when it is played quickly, the picture we see is continuous.
PAL (TV broadcast format in Europe, Asia, Australia and other places) and SECAM (TV broadcast format in France, Russia, some Africa and other places) stipulate that the update rate is 25fps, while NTSC (TV broadcast in the United States, Canada, Japan and other places) Format) stipulates that its update rate is 29.97 fps. Early film films were shot at a slightly slower 24fps.
Adjacent pictures in a video sequence are usually very similar, that is, they contain a lot of redundancy. We can use certain methods to eliminate this redundancy and improve the compression ratio.
Frame/Group (GOP)
Image frames are processed in groups, and this group is GOP (Group of pictures). The first frame of each group (usually the first frame) does not use motion estimation when encoding. Such frames are called Intra frames or I frames. The other frames in the group use Inter frame, which is usually P frame. This encoding method is usually called IPPPP, which means that the first frame is an I frame when encoding, and the other frames are P frames.
I frames can be used to implement fast forward, rewind, or other random access functions. When a new client starts to browse the content stream, the encoder will automatically insert I-frames at fixed time intervals or as needed. The disadvantage of the I frame is that it consumes more bits. On the other hand, it does not generate many artifacts due to lost data.
P-frames represent predictive inter-frames, using early I-frames and/or P-frames as a reference. Compared with I-frames, P-frames usually require fewer bits, but it has a disadvantage that it is sensitive to transmission errors due to its high dependence on early P-frames and/or I-frames.
When making predictions, not only can the current frame be predicted from the past frame, but also the future frame can be used to predict the current frame. Of course, when encoding, the future frame must be encoded earlier than the current frame, that is, the encoding sequence and the playback sequence are different. Usually such a current frame is predicted by using past and future I frames or P frames at the same time, which is called a bidirectional prediction frame, that is, a B frame. An example of the coding sequence of this coding method is IBBPBBPBB.
The B frame is a bi-predictive inter frame, which uses the early reference frame I frame and the future frame P frame as references. Using B frames will increase the delay.
P-frames can only refer to previous I-frames or P-frames, while B-frames can refer to previous or subsequent I-frames or P-frames.
Some network video coding products can support user-defined GOP length (some products are called I frame interval), which will determine how many P frames should be sent before sending another I frame. By reducing the frequency of I frames (longer GOP), you can lower the bit rate and reduce the video file size. However, if there is congestion on the network, the video quality may be degraded due to network packet loss.
Generally, if the unit is time, the GOP length is set to 1s or 2s, that is, there is one I frame in 25 (30) frames or one I frame in 50 (60) frames. If other units are used, the GOP or I frame interval can be set to 25/30 or 50/60.
Coding level
In security video surveillance coding products, H.264 coding supports 3 coding levels, from low to high: Baseline, Main and High.
Baseline level supports I/P frames, Main level provides I/P/B frames, supports non-interlaced (Progressive) and interlaced (Interlaced), High level adds 8×8 intra prediction, custom quantization, and lossless on the basis of Main Video encoding and more YUV formats (such as 4:4:4), etc.
The coding level of H.264 is mainly for compatibility, and different specifications can be applied on the platform at the same level. As for the [email protected], [email protected], [email protected] formats, the stream levels are at different levels. The larger the value, the larger the stream, which consumes more resources. So in terms of code stream, [email protected]<[email protected]<[email protected].
H.265 is divided into two coding level profiles, Main and High, and different Level levels and Tier levels are also defined.
- Profile specifies which coding tools and algorithms are used in the code stream.
- Level specifies the decoder processing burden and storage capacity parameters corresponding to a given Profile and Tier, which mainly include the sampling rate, resolution, maximum code rate, minimum compression rate, and the capacity of the decoded image buffer (DPB). ), the capacity of the coded image buffer area (CPB), etc.
- Tier specifies the bit rate of each level.
Bit rate and control method
The code stream (bit rate) control method in video encoding is mainly divided into: VBR (dynamic bit rate) and CBR (static bit rate). The size of the bit rate determines the size of the video file. We can calculate the size of the video file by the bit rate, see article-How to calculate the file size of security video.
VBR
Variable Bitrate, that is, dynamic bit rate. That is, there is no fixed bit rate, and the compression software instantly determines what bit rate to use according to the audio and video data during compression. This is a way of taking into account the file size on the premise of quality.
VBR is also known as dynamic bit rate encoding. When using this method, you can choose various transition stages from the worst audio and video quality/maximum compression ratio to the best audio and video quality/lowest compression ratio. When encoding a video file, the program will try to maintain the quality of the entire selected file, and will select a bit rate suitable for different parts of the audio and video file for encoding. The main advantage is that the audio and video can roughly meet our quality requirements, but the disadvantage is that the compressed file size cannot be accurately estimated during encoding.
CBR
Constants Bit Rate, or fixed bit rate, means static (constant) bit rate. CBR is a compression method with a fixed sampling rate. The advantage is that it compresses quickly and can be supported by most software and equipment. The disadvantage is that it takes up relatively large space and the effect is not very satisfactory. It has been gradually replaced by VBR.
Other stream control methods
In H.265 encoding, Huawei HiSilicon introduced the AVBR concept, A is advanced, which can save 30% of the code stream compared to the ordinary VBR method.
Some manufacturers have combined the advantages of VBR and CBR to put forward the concept of CVBR code stream control. When the image content is still, bandwidth is saved, and when Motion occurs, the bandwidth saved in the previous period is used to improve the image quality as much as possible, so as to achieve the purpose of taking into account both bandwidth and image quality. This method usually allows the user to enter the maximum code rate and the minimum code rate. When it is stationary, the code rate is stable at the minimum code rate. When in motion, the code rate is greater than the minimum code rate, but does not exceed the maximum code rate.
Metrics
The pros and cons of video coding technology can be measured from two aspects: computational complexity and compression quality.
In terms of computational complexity, the lower the computational complexity of an ideal encoder, the better. In terms of compression quality, the bit rate and lossy degree of the compressed video must be considered at the same time. After compression, the lower the bit rate and the degree of loss, the better. There is a trade-off relationship between the two. The ideal encoder aims to provide the best compromise between the bit rate and the degree of loss.
Under normal circumstances, there is also a trade-off relationship between the computational complexity of the encoder and the compression quality, which depends on the application. For example, when the application is the storage of video data, a design with higher computational complexity and compression quality can be selected. When the application is a video conference or mobile phone video call, it is limited by the requirements of instant (real-time) communication or limited computing resources, and a design with lower computing complexity and compression quality may be selected.
Since the quality of the encoded video is ultimately judged by the human eye, when measuring the degree of loss, a video quality measurement standard consistent with human visual perception should be used.


Leave a Reply
Want to join the discussion?Feel free to contribute!